使用可选代理进行扩展分析
本教程演示如何使用CASSIA的可选代理进行更深入的分析和验证,从提供的标记基因文件开始。这些代理可以帮助您:
- 评估注释的不确定性
- 提升特定细胞簇的注释质量
- 比较相似的细胞类型
- 执行亚聚类并分析亚群
1. 不确定性量化
运行多次注释迭代以提高准确性并评估结果的稳定性:
假设单次准确率为80%,通过重复注释5次,准确率将提高到约95%。

# 运行多次迭代 runCASSIA_batch_n_times( n = 5, marker = markers_unprocessed, output_name = "CASSIA_Uncertainty", tissue = "large intestine", species = "human", max_workers = 6, # 每批次使用的工作进程数 batch_max_workers = 1 # 并行运行的批次数 ) # 计算相似度评分 runCASSIA_similarity_score_batch( marker = markers_unprocessed, file_pattern = paste0(output_name, "_Uncertainty_*_summary.csv"), # 不确定性结果的文件模式 output_name = "cs_results", max_workers = 6 )R
结果包含每个细胞簇的共识细胞类型注释和共识相似度评分。相似度评分低于75的细胞簇应标记为需要进一步检查,因为这表明存在潜在的注释不确定性或异质性群体。
共识相似度评分提供了多次迭代中注释稳定性的量化指标。评分越高表示对注释的置信度越高。
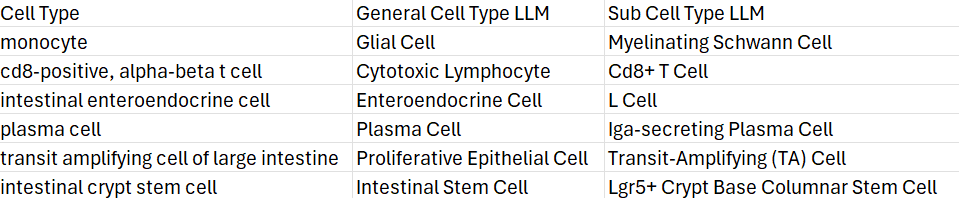

2. 对选定细胞簇进行注释增强
单核细胞簇有时会被注释为免疫细胞和神经元/胶质细胞的混合群体。
这里我们使用注释增强代理来更详细地测试这些假设。
# 对高线粒体含量的细胞簇运行验证增强 runCASSIA_annotationboost( full_result_path = paste0(output_name, "_summary.csv"), marker = markers_unprocessed, output_name = "monocyte_annotationboost2", cluster_name = "monocyte", major_cluster_info = "Human Large Intestine", num_iterations = 5, model = "anthropic/claude-sonnet-4.6", provider = "openrouter", conversations_json_path = paste0(output_name, "_conversations.json") # 提供注释上下文 )R
将生成详细的报告。该报告提供对单核细胞簇的深入分析。部分结果如下所示:

3. 比较细胞类型
当您完成默认的CASSIA流程后仍对某个细胞类型不确定时,可以使用此代理。您可以使用此代理获得更可靠的亚型注释。这里我们以浆细胞簇为例,区分它更像是一般的浆细胞还是其他细胞类型。默认使用的模型是基于思维链的高级模型。
#此处的标记基因是从CASSIA之前的结果中复制的。 marker="IGLL5, IGLV6-57, JCHAIN, FAM92B, IGLC3, IGLC2, IGHV3-7, IGKC, TNFRSF17, IGHG1, AC026369.3, IGHV3-23, IGKV4-1, IGKV1-5, IGHA1, IGLV3-1, IGLV2-11, MYL2, MZB1, IGHG3, IGHV3-74, IGHM, ANKRD36BP2, AMPD1, IGKV3-20, IGHA2, DERL3, AC104699.1, LINC02362, AL391056.1, LILRB4, CCL3, BMP6, UBE2QL1, LINC00309, AL133467.1, GPRC5D, FCRL5, DNAAF1, AP002852.1, AC007569.1, CXorf21, RNU1-85P, U62317.4, TXNDC5, LINC02384, CCR10, BFSP2, APOBEC3A, AC106897.1" compareCelltypes( tissue = "large intestine", celltypes = c("Plasma Cells","IgA-secreting Plasma Cells","IgG-secreting Plasma Cells","IgM-secreting Plasma Cells"), marker = marker, species = "human", output_file = "plasama_cell_subtype" )R
4. 亚聚类分析
此代理可用于研究亚聚类群体,如T细胞群体或成纤维细胞簇。我们建议首先应用默认的CASSIA,然后对目标细胞簇应用Seurat流程进行亚聚类,并获取FindAllMarkers结果以在此处使用。
这里我们以之前分析的CD8阳性αβ T细胞簇为例展示结果。该细胞簇是CD8群体与其他非CD8 T细胞类型的混合体。
# 亚聚类示例代码(简化版) # large <- readRDS("seurat_object.rds") # cd8_cells <- subset(large, cell_ontology_class == "cd8-positive, alpha-beta t cell") # # # 标准Seurat预处理流程 # cd8_cells <- NormalizeData(cd8_cells) %>% # FindVariableFeatures() %>% # ScaleData() %>% # RunPCA() %>% # FindNeighbors(dims = 1:20) %>% # FindClusters(resolution = 0.3) %>% # RunUMAP(dims = 1:20) # # # 查找标记基因并保存结果 # cd8_markers <- FindAllMarkers(cd8_cells, only.pos = TRUE, min.pct = 0.1, logfc.threshold = 0.25) %>% # filter(p_val_adj < 0.05) # write.csv(cd8_markers, "cd8_subcluster_markers.csv") marker_sub=loadExampleMarkers_subcluster() runCASSIA_subclusters(marker = marker_sub, major_cluster_info = "cd8 t cell", output_name = "subclustering_results", tissue = "lung", species = "human") #为了更好地捕获混合信号,可以将major_cluster_info指定为"cd8 t cell mixed with other celltypes" runCASSIA_subclusters(marker = marker_sub, major_cluster_info = "cd8 t cell mixed with other celltypes", output_name = "subclustering_results2", tissue = "lung", species = "human")R
将生成一个包含亚聚类结果的CSV文件。下图显示了输出示例,包含每个亚簇的详细注释和推理过程。

建议对亚聚类运行CS评分以获得更可靠的答案。
runCASSIA_n_subcluster(n=5, marker_sub, "cd8 t cell", "subclustering_results_n", max_workers = 5, n_genes=50L, tissue = "lung", species = "human") # 计算相似度评分 similarity_scores <- runCASSIA_similarity_score_batch( marker = marker_sub, file_pattern = "subclustering_results_n_*.csv", output_name = "subclustering_uncertainty", max_workers = 6 )R
有关标记基因文件准备和基础注释的更多详情,请参阅其他教程。如果您有关于附加代理或改进的建议,欢迎在GitHub上贡献。